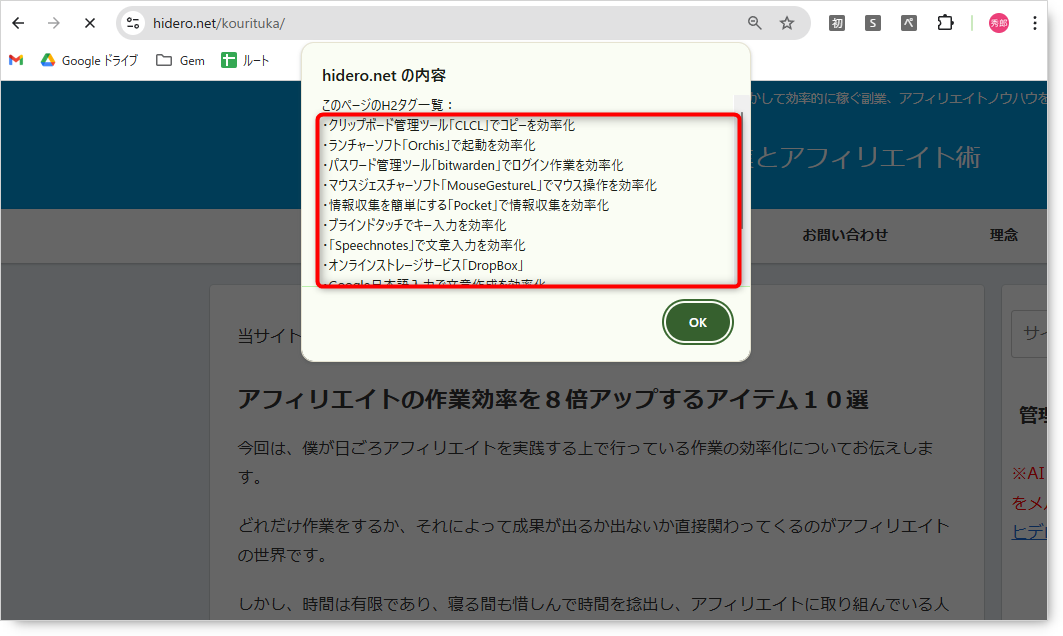
今見ているWebページの中身を取得(スクレイピング)してみます。
前の講座と同様にContent Scripts(コンテンツスクリプト) を使用します。
今回は実習として、「僕のサイトのページを開いたら、h2タグを取得する」というシンプルな機能を作ってみましょう。
まずはデスクトップなど任意の場所に新しいフォルダを作成します。名前はh2tag-get等、何でも大丈夫です。
このフォルダの中に「manifest.json」、「content.js」という2つのファイルを作成します。
テキストエディタ(メモ帳やVS Codeなど)を開いて、以下のコードをコピー&ペーストして保存してください。
manifest.json (設定ファイル)
{
"name": "H2タグ取得",
"version": "1.0",
"manifest_version": 3,
"content_scripts": [
{
"matches": ["https://hidero.net/*"],
"js": ["content.js"]
}
]
}
1. content_scripts
Webページの中で実行するプログラムを設定します。
2. matches
「どのURLの時に動かすか」を指定します。
今回は https://hidero.net/* と指定したので、僕のサイトページを開いた時だけ動きます。
なお、matches: [“<all_urls>”]とすると「インターネット上のすべてのWebサイト」で動作させることができます。
ただし、スクレイピングの機能などは許可されてないサイトもあるのでここでは僕のサイトに絞って設定しています。
3. js
「実行するJavaScriptファイル」を指定します。
ここでは content.js を読み込むように設定しました。
content.js (Javascript)
指定したページを開いたときに実行されるJavascriptです。
const h2List = document.querySelectorAll("h2");
let message = "このページのH2タグ一覧:\n";
for (const h2 of h2List) {
message += "・" + h2.innerText + "\n";
}
if (h2List.length > 0) {
alert(message);
}
このコードは、通常のJavascriptと全く同じです。
1. document.querySelectorAll(“h2”)
ページ内にある h2タグをすべて取得する指定です。
もし h2 を a に変えればリンク一覧になりますし、img に変えれば画像一覧になります。
2. for (const h2 of h2List)
取得したタグは複数ある(リストになっている)ので、それを一個ずつ取り出して処理するための「繰り返し文」です。
3. h2.innerText
タグの中にある「目に見える文字」だけを取り出します。
(例:<h2>こんにちは</h2> から 「こんにちは」 だけを抜き出す)
4. alert(message)
ブラウザの上部にメッセージウィンドウを表示します。
一番手軽に結果を確認できる方法です。
実行
「拡張機能をインストールして実行する」を参考にして拡張機能インストールして、僕のサイト(例:https://hidero.net/kourituka/)にアクセスするとページが開いた瞬間に、画面中央に「H2タグ一覧」が表示されることが確認できます。